关于 SeaTunnel
![]()
![]()
SeaTunnel 是一个多模态、高性能、分布式的数据集成平台。 它用统一的作业模型帮助团队在数据库、文件系统、数据湖、消息系统之间完成数据读取、转换与同步。
从这里开始
如果您是第一次接触 SeaTunnel,建议按下面的顺序阅读:
- 快速入门总览:先建立整体路径
- SeaTunnel 引擎快速开始:先跑通第一个任务
- 作业配置指南:开始编写真实作业
- 工作原理:先理解运行模型,再进入更深层架构
如果您已经有 Flink 或 Spark 运行环境,也可以直接跳到 Flink 引擎快速开始 或 Spark 引擎快速开始。
SeaTunnel 能帮您做什么
SeaTunnel 面向的是数据团队最常见、也最先要交付的几类任务:
- 在多种系统之间搬运数据:包括数据库、消息队列、文件系统、对象存储、数据湖和 SaaS 系统
- 同时支持批处理和流处理:同一套连接器模型可以覆盖全量、增量、CDC 和实时同步
- 让作业定义保持清晰:一个 SeaTunnel 作业仍然主要由
env、source、transform、sink四部分组成 - 降低运行复杂度:SeaTunnel 关注高吞吐、较低依赖成本和实用的运行可观测性
团队为什么会选择 SeaTunnel
- 连接器优先的设计:SeaTunnel 提供统一的连接器接口(Connector API),Source、Transform、Sink 可以跨引擎复用
- 引擎选择灵活:可以直接从 SeaTunnel 引擎(Zeta)起步,也可以运行在 Flink 或 Spark 上
- 面向真实同步场景:多表同步、CDC、大规模作业执行都是第一类使用场景
- 运行态可观察:作业能够暴露运行指标和任务信息,方便理解吞吐、延迟和稳定性
- 适合从小到大演进:既可以本地先跑一个简单任务,也可以逐步扩展到更复杂的集群部署
用一张图理解 SeaTunnel
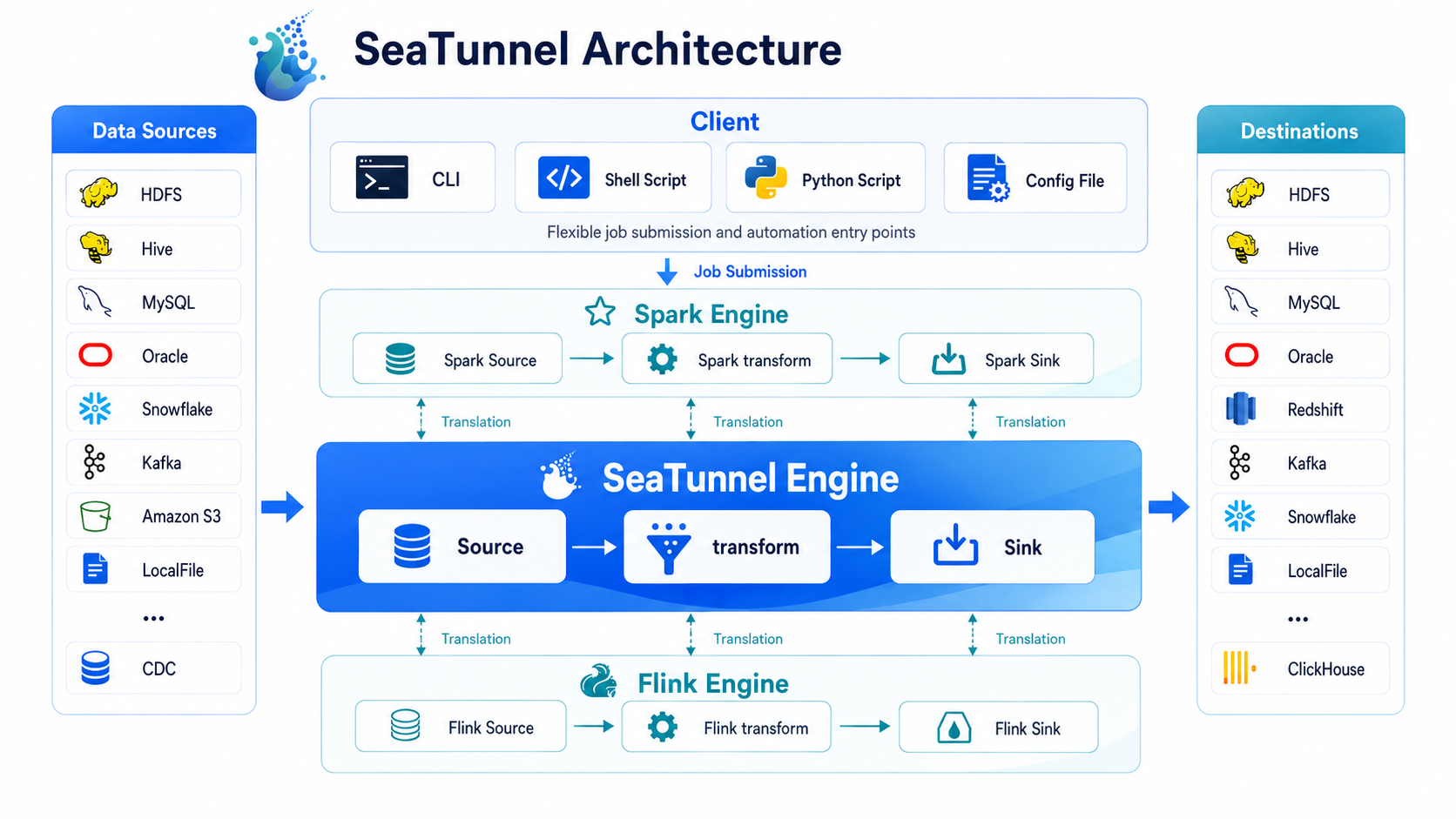
您可以先抓住三个最重要的理解点:
1. SeaTunnel 作业本质上是一条数据管道
您用配置文件描述作业,SeaTunnel 再把它执行成一条从 Source(读取) 到 Transform(转换) 再到 Sink(写入) 的数据处理链路。
2. 连接器决定读什么、写到哪里
SeaTunnel 提供了丰富的 源连接器、 目标连接器 和 数据转换。 如果有特殊需求,您也可以自行扩展这些插件类型。
3. 引擎决定这条作业跑在哪儿
SeaTunnel 引擎(Zeta) 是默认选择,也是大多数新用户最推荐的起点。 如果您已经在使用 Flink 或 Spark,SeaTunnel 也可以把同一套连接器作业模型运行在这些平台上。
如何选择运行引擎
| 引擎 | 推荐起点 | 适用场景 |
|---|---|---|
| SeaTunnel 引擎(Zeta) | 推荐大多数新用户先从这里开始 | 希望以最短路径跑通 SeaTunnel 作业 |
| Apache Flink | 适合已有 Flink 环境的团队 | 已经维护 Flink 集群,希望让 SeaTunnel 接入现有平台 |
| Apache Spark | 适合已有 Spark 环境的团队 | 主要是批处理任务,希望复用现有 Spark 技术栈 |
继续阅读
- 工作原理:以新手能接受的层次理解运行模型
- 配置文件简介:开始写真实作业
- 数据连接器总览:先确认读写方向,再进入具体连接器参数页
- 系统架构概览:当您需要深入内部设计时再继续往下读
- 常见问题:快速处理常见使用、CDC 与配置问题
获取帮助与加入社区
- 开发环境搭建:如果您要本地构建或调试 SeaTunnel
- 贡献路径:如果您想从最小、最稳妥的范围开始参与贡献
- 贡献插件:如果您准备贡献连接器或 transform 插件
- GitHub Issues、Slack 和 dev 邮件列表:如果您需要社区帮助
谁在使用 SeaTunnel
SeaTunnel 拥有大量用户。您可以在用户中找到有关他们的更多信息。