Apache SeaTunnel (Incubating) 与 Apache Inlong (Incubating) 的5月联合Meetup中,第二位分享的嘉宾是来自白鲸开源的高级工程师李宗文。在使用Apache SeaTunnel (Incubating) 的过程中,他发现了 Apache SeaTunnel (Incubating) 存在的四大问题:Connector实现次数多、参数不统一、难以支持多个版本的引擎以及引擎升级难的问题。为了解决以上的难题,李宗文将目标放在将Apache SeaTunnel (Incubating)与计算引擎进行解耦,重构其中Source与Sink API,实现改良了开发体验。
本次演讲主要包含四个部分:
- Apache SeaTunnel (Incubating)重构的背景和动机
- Apache SeaTunnel (Incubating)重构的目标
- Apache SeaTunnel (Incubating)重构整体的设计
- Apache SeaTunnel (Incubating) Source API的设计
- Apache SeaTunnel (Incubating) Sink API的设计
李宗文
白鲸开源 高级工程师
Apache SeaTunnel(Incubating)
& Flink Contributor, Flink CDC & Debezium Contributor
01 重构的背景与动机
01 Apache SeaTunnel(Incubating)与引擎耦合
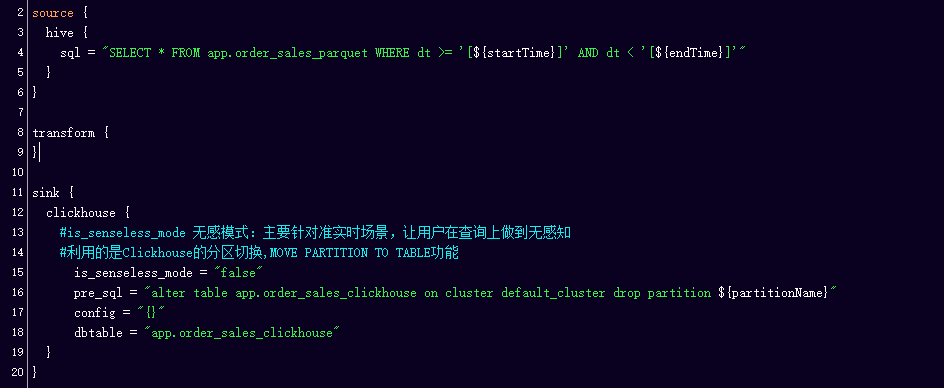
用过Apache SeaTunnel (Incubating) 的小伙伴或者开发者应该知道,目前Apache SeaTunnel (Incubating) 与引擎完全耦合,完全基于Spark、Flink开发,其中的配置文件参数都基于Flink、Spark引擎。从贡献者和用户的角度出发,我们能发现一些问题。
从贡献者的角度:反复实现Connector,没有收获感;潜在贡献者由于引擎版本不一致无法贡献社区;
从用户的角度:目前很多公司采用Lambda架构,离线作业使用Spark,实时作业使用Flink, 使用中就会发现SeaTunnel 的Connector可能Spark有,但是Flink没有,以及两个引擎对于同一存储引擎的Connector的参数也不统一,有较高的使用成本,脱离了SeaTunnel简单易用的初衷;还有用户提问说目前支不支持Flink的1.14版本,按照目前SeaTunnel的架构,想要支持Flink的1.14就必须抛弃之前的版本,因此这也会对之前版本的用户造成很大的问题。
因此,我们不管是做引擎升级或者支持更多的版本的用户都很困难。
另外Spark和Flink都采用了Chandy-lamport算法实现的Checkpoint容错机制,也在内部进行了DataSet与DataStream的统一,以此为前提我们认为解耦是可行的。
02 Apache SeaTunnel(Incubating)与引擎解耦
因此为了解决以上提出的问题,我们有了以下的目标:
- Connector只实现一次:针对参数不统一、Connector多次实现的问题,我们希望实现一个统一的Source 与Sink API;
- 支持多个版本的Spark与Flink引擎:在Source与Sink API上再加入翻译层去支持多个版本与Spark和Flink引擎,解耦后这个代价会小很多。
- 明确Source的分片并行逻辑和Sink的提交逻辑:我们必须提供一个良好的API去支持Connector开发;
- 支持实时场景下的数据库整库同步:这个是目前很多用户提到需要CDC支持衍生的需求。我之前参与过Flink CDC社区,当时有许多用户提出在CDC的场景中,如果直接使用Flink CDC的话会导致每一个表都持有一个链接,当遇到需要整库同步需求时,千张表就有千个链接,该情况无论是对于数据库还是DBA都是不能接受的,如果要解决这个问题,最简单的方式就是引入Canal、Debezium等组件,使用其拉取增量数据到Kafka等MQ做中间存储,再使用Flink SQL进行同步,这实际已经违背了Flink CDC最早减少链路的想法,但是Flink CDC的定位只是一个Connector,无法做全链路的需求,所以该proposal在Flink CDC社区中没有被提出,我们借着本次重构,将proposa提交到了SeaTunnel社区中。
- 支持元信息的自动发现与存储:这一部分用户应该有所体验,如Kafka这类存储引擎,没有记录数据结构的功能,但我们在读取数据时又必须是结构化的,导致每次读取一个topic之前,用户都必须定义topic的结构化数据类型,我们希望做到用户只需要完成一次配置,减少重复的操作。
可能也有同学有疑惑为什么我们不直接使用Apache Beam,Beam的Source分为BOUNDED与UNBOUNDED,也就是需要实现两遍,并且有些Source与Sink的特性也不支持,具体所需的特性在后面会提到;
03 Apache SeaTunnel(Incubating)重构整体的设计
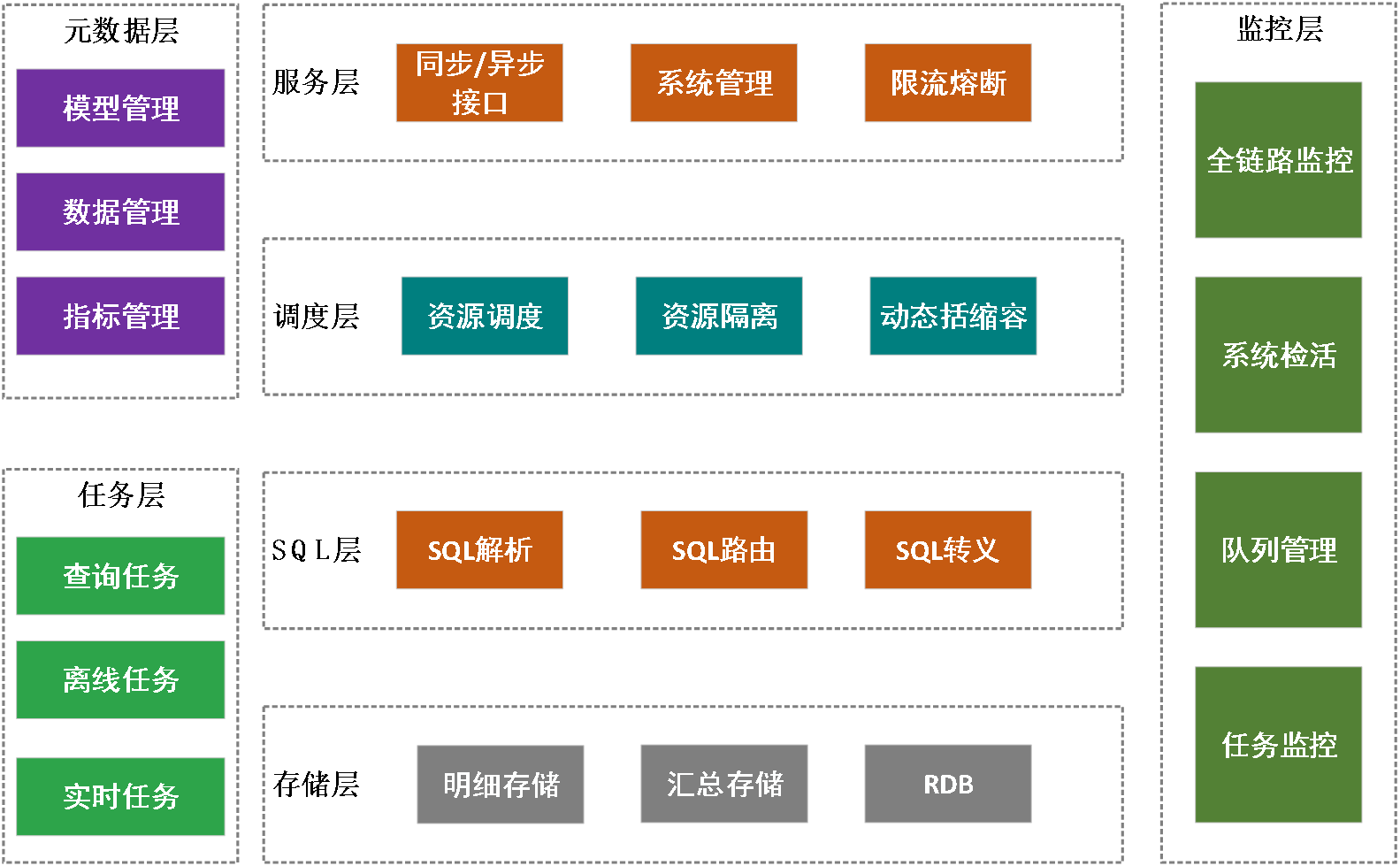
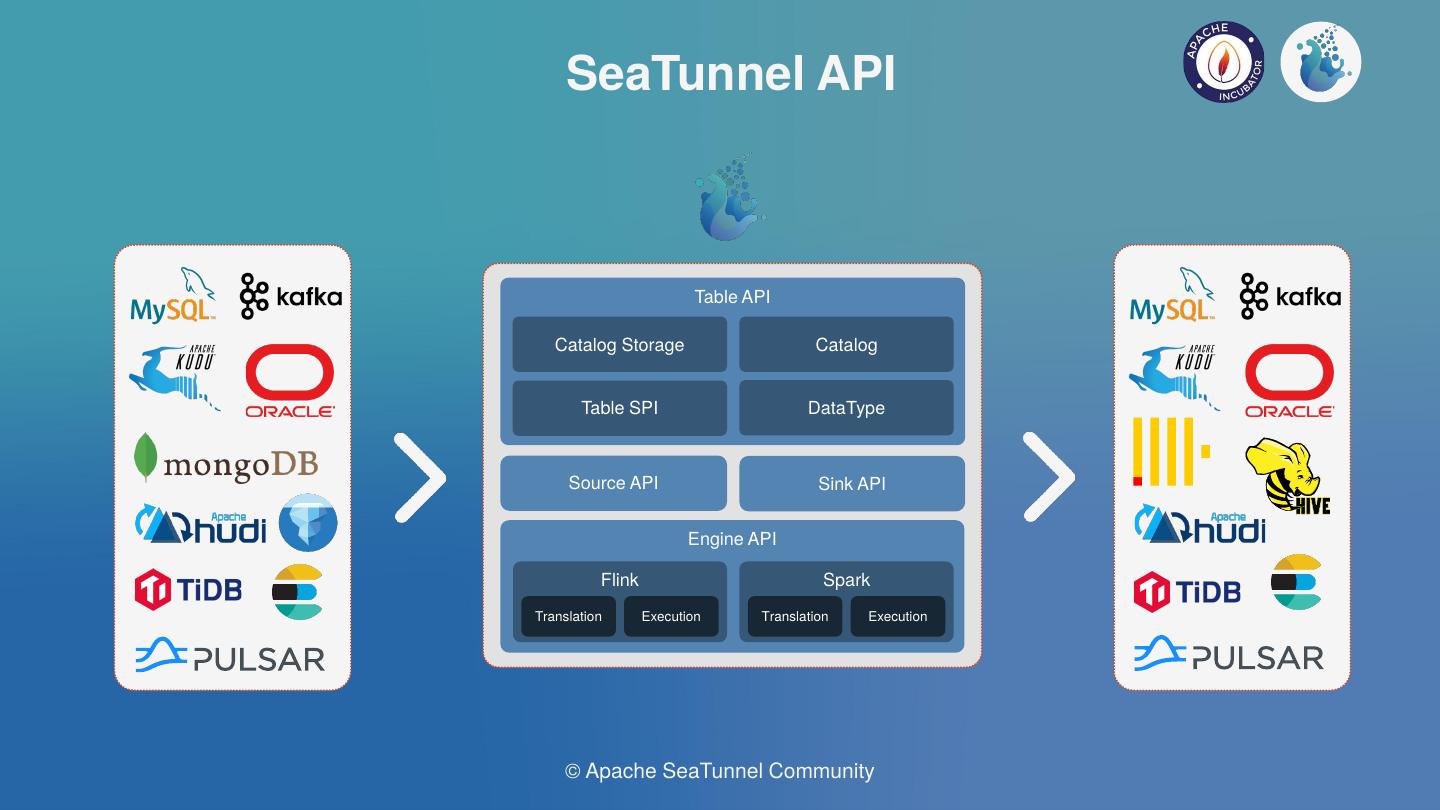
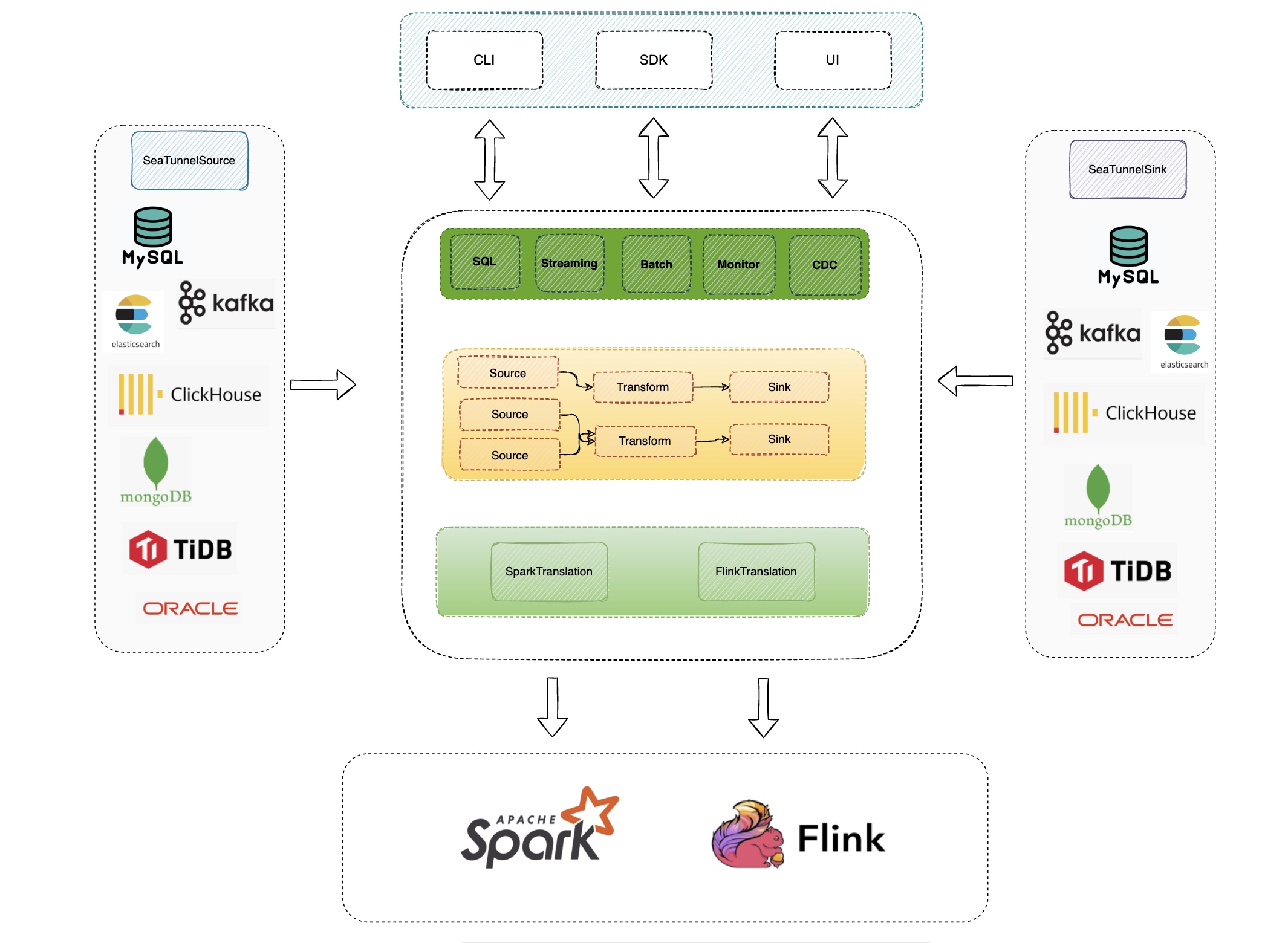
Apache SeaTunnel(Incubating) API总体结构的设计如上图;
Source & Sink API:数据集成的核心API之一,明确Source的分片并行逻辑和Sink的提交逻辑,用于实现Connector;
Engine API:
Translation: 翻译层,用于将SeaTunnel的Souce与Sink API翻译成引擎内部可以运行的Connector;
Execution:执行逻辑,用于定义Source、Transform、Sink等操作在引擎内部的执行逻辑;
Table API:
Table SPI:主要用于以SPI的方式暴露Source与Sink接口,并明确Connector的必填与可选参数等;
DataType:SeaTunnel的数据结构,用于隔离引擎,声明Table Schema等;
Catalog:用于获取Table Scheme、Options等;
Catalog Storage: 用于存储用户定义Kafka等非结构化引擎的Table Scheme等;
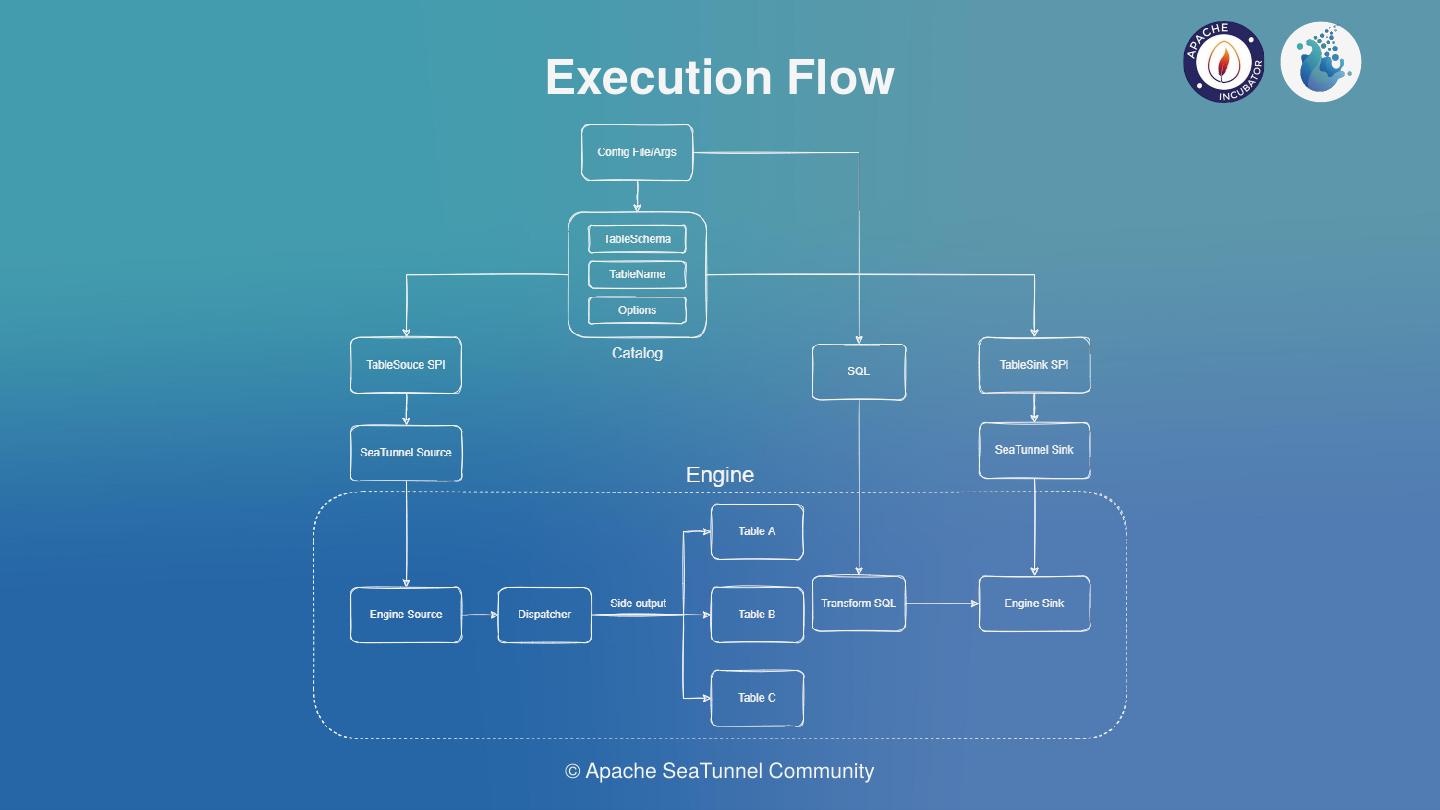
从上图是我们现在设想的执行流程:
- 从配置文件或UI等方式获取任务参数;
- 通过参数从Catalog中解析得到Table Schema、Option等信息;
- 以SPI方式拉起SeaTunnel的Connector,并注入Table信息等;
- 将SeaTunnel的Connector翻译为引擎内部的Connector;
- 执行引擎的作业逻辑,图中的多表分发目前只存在CDC整库同步场景下,其他Connector都是单表,不需要分发逻辑;
从以上可以看出,最难的部分是如何将Apache SeaTunnel(Incubating) 的Source和Sink翻译成引擎内部的Source和Sink。
当下许多用户不仅把Apache SeaTunnel (Incubating) 当做一个数据集成方向的工具,也当做数仓方向的工具,会使用很多Spark和Flink的SQL,我们目前希望能够保留这样的SQL能力,让用户实现无缝升级。
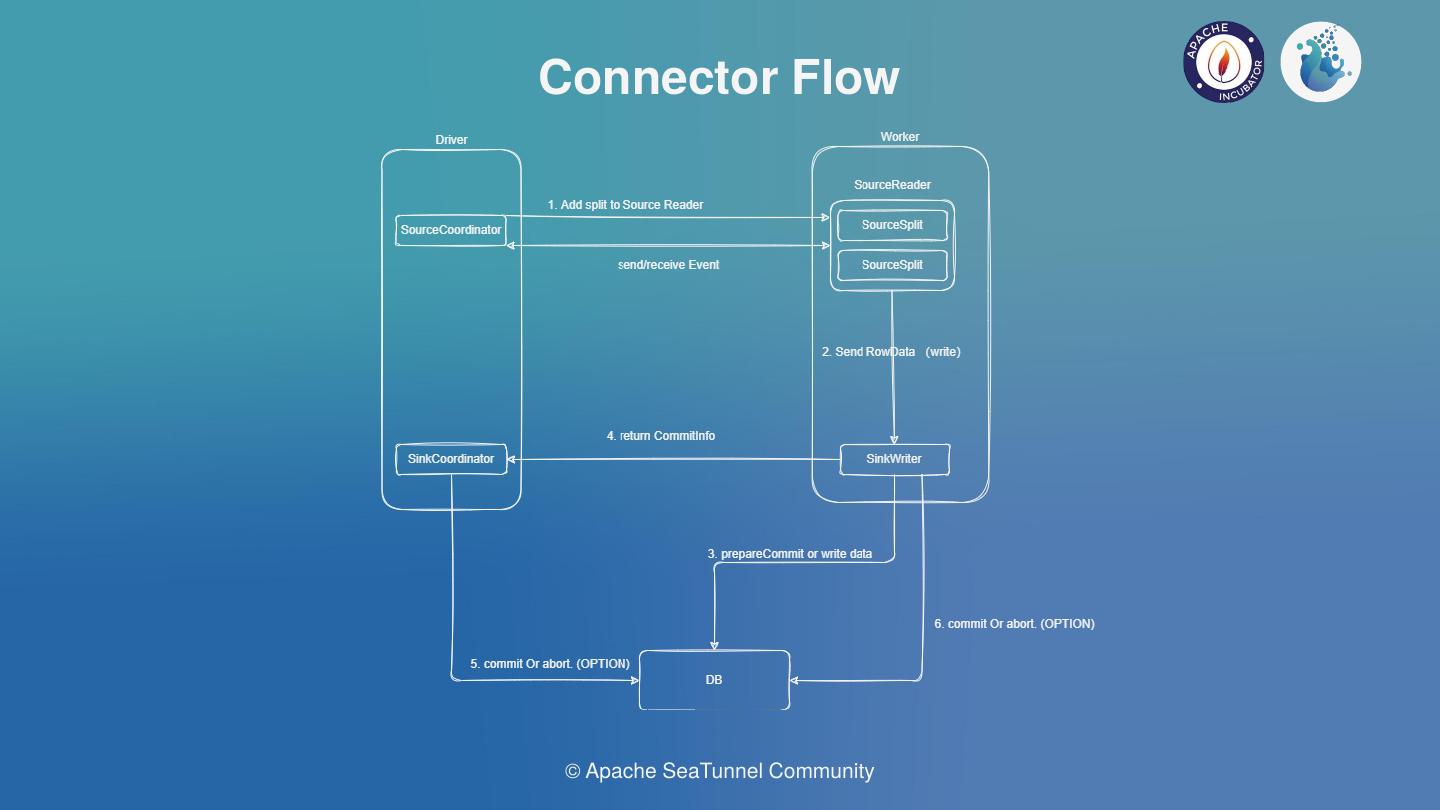
根据我们的调研,如上图,是对Source与Sink的理想执行逻辑,由于SeaTunnel以WaterDrop孵化,所以图上的术语偏向Spark;
理想情况下,在Driver上可以运行Source和Sink的协调器,然后Worker上运行Source的Reader和Sink的Writer。在Source协调器方面,我们希望它能支持几个能力。
一、是数据的分片逻辑,可以将分片动态添加到Reader中。
二、是可以支持Reader的协调。SourceReader用于读取数据,然后将数据发送到引擎中流转,最终流转到Source Writer中进行数据写入,同时Writer可以支持二阶段事务提交,并由Sink的协调器支持Iceberg等Connector的聚合提交需求;
04 Source API
通过我们的调研,发现Source所需要的以下特性:
- 统一离线和实时API:Source只实现一次,同时支持离线和实时;
- 能够支持并行读取:比如Kafka每一个分区都生成一个的读取器,并行的执行;
- 支持动态添加分片:比如Kafka定于一个topic正则,由于业务量的需求,需要新增一个topic,该Source API可以支持我们动态添加到作业中。
- 支持协调读取器的工作:这个目前只发现在CDC这种Connector需要支持。CDC目前都是基于Netfilx的DBlog并行算法去支持,该情况在全量同步和增量同步两个阶段的切换时需要协调读取器的工作。
- 支持单个读取器处理多张表:即由前面提到的支持实时场景下的数据库整库同步需求;

对应以上需求,我们做出了基础的API,如上图,目前代码以提交到Apache SeaTunnel(Incubating)的社区中api-draft分支,感兴趣的可以查看代码详细了解。
如何适配Spark和Flink引擎
Flink与Spark都在后面统一了DataSet与DataStream API,即能够支持前两个特性,那么对于剩下的3个特性:
- 如何支持动态添加分片?
- 如何支持协调读取器?
- 如何支持单个读取器处理多张表?
带着问题,进入目前的设计。
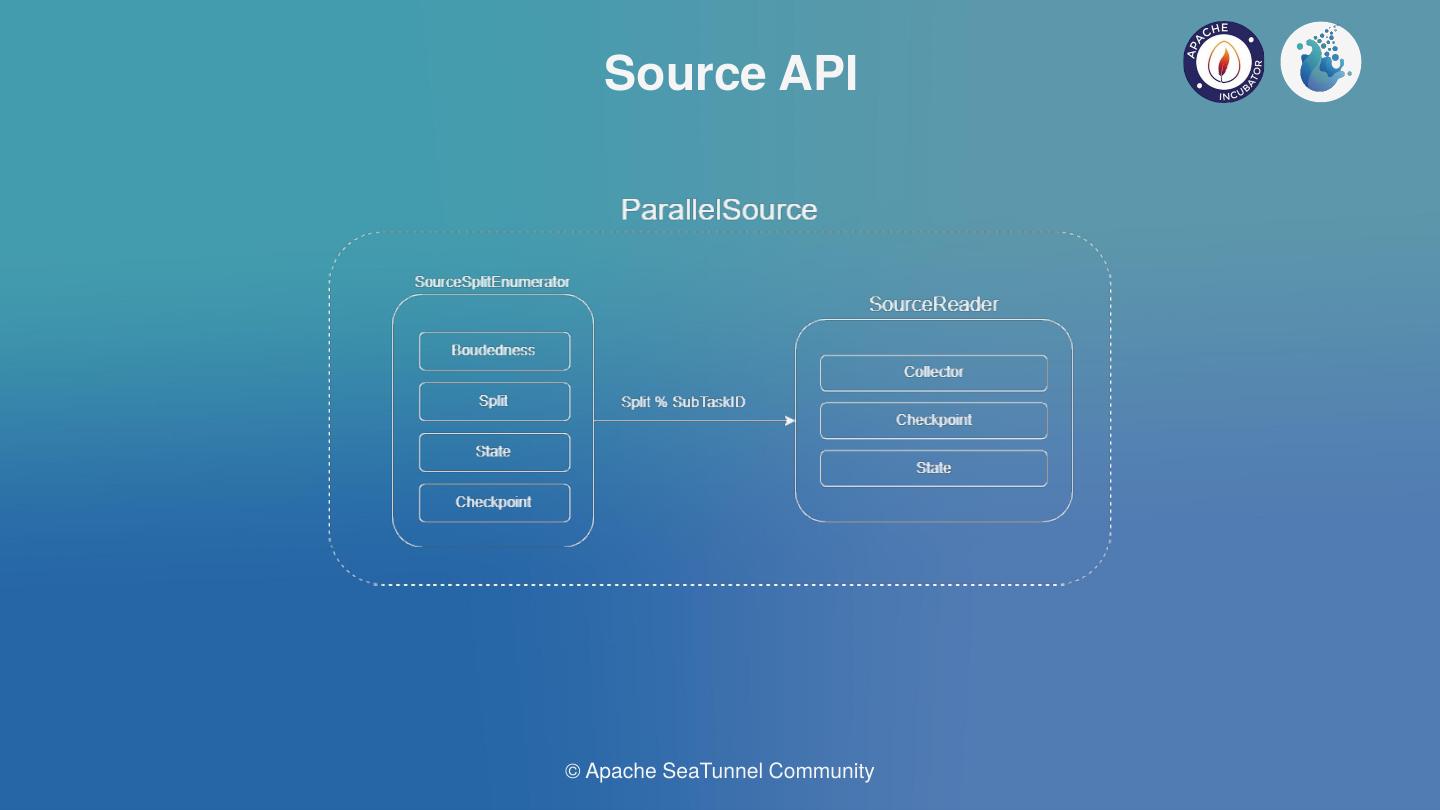
我们发现除了CDC之外,其他Connector是不需要协调器的,针对不需要协调器的,我们会有一个支持并行的Source,并进行引擎翻译。
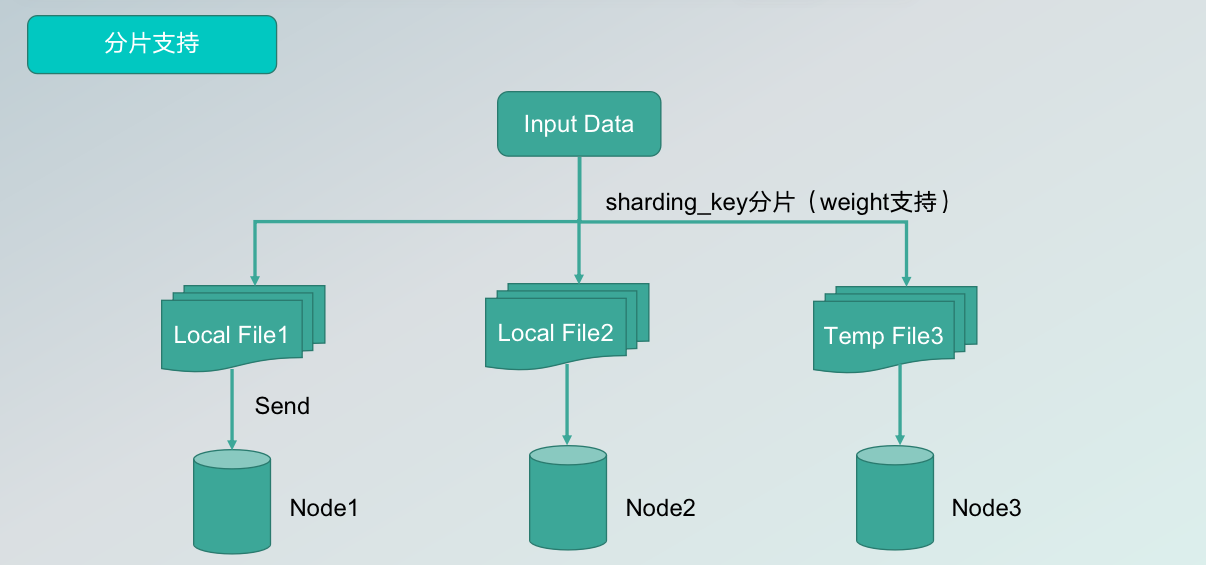
如上图中左边是一个分片的enumerator,可以列举source需要哪些分片,有哪些分片,实时进行分片的枚举,随后将每个分片分发到真正的数据读取模块SourceReader中。对于离线与实时作业的区分使用Boundedness标记,Connector可以在分片中标记是否有停止的Offset,如Kafka可以支持实时,同时也可以支持离线。ParallelSource可以在引擎设置任意并行度,以支持并行读取。
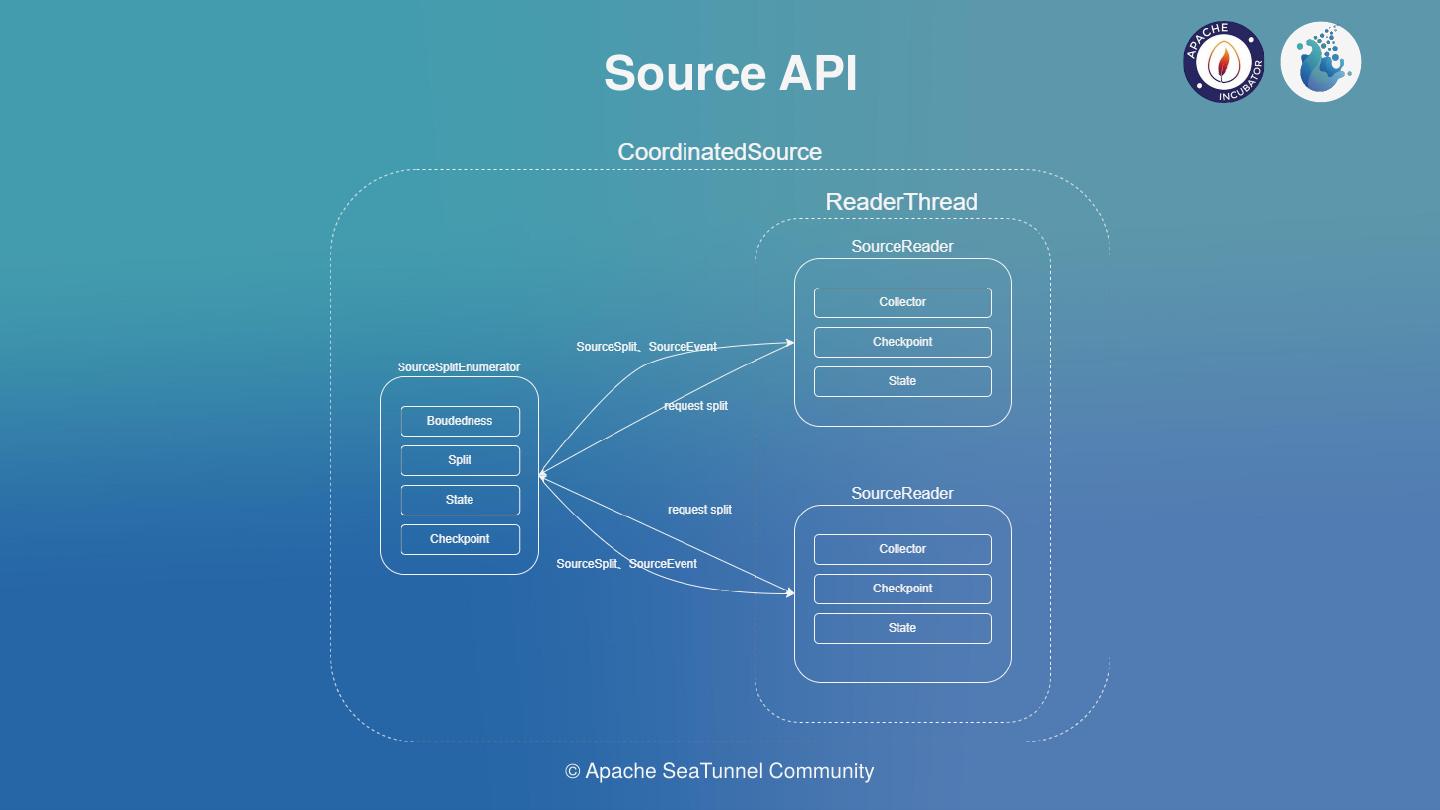
在需要协调器的场景,如上图,需要在Reader和Enumerator之间进行Event传输, Enumerator通过Reader发送的Event进行协调工作。Coordinated Source需要在引擎层面保证单并行度,以保证数据的一致性;当然这也不能良好的使用引擎的内存管理机制,但是取舍是必要的;
对于最后一个问题,我们如何支持单个读取器处理多张表。这会涉及到Table API层,通过Catalog读取到了所有需要的表后,有些表可能属于一个作业,可以通过一个链接去读取,有些可能需要分开,这个依赖于Source是怎么实现的。基于这是一个特殊需求,我们想要减少普通开发者的难度,在Table API这一层,我们会提供一个SupportMultipleTable接口,用于声明Source支持多表的读取。Source在实现时,要根据多张表实现对应的反序列化器。针对衍生的多表数据如何分离,Flink将采用Side Output机制,Spark预想使用Filter或Partition机制。
05 Sink API
目前Sink所需的特性并不是很多,经过调研目前发现有三个需求:
- 幂等写入,这个不需要写代码,主要看存储引擎是否能支持。
- 分布式事务,主流是二阶段提交,如Kafka都是可以支持分布式事务的。
- 聚合提交,对于Iceberg、hoodie等存储引擎而言,我们不希望有小文件问题,于是期望将这些文件聚合成一个文件,再进行提交。
基于以上三个需求,我们有对应的三个API,分别是SinkWriter、SinkCommitter、SinkAggregated Committer。SinkWriter是作为基础写入,可能是幂等写入,也可能不是。SinkCommitter支持二阶段提交。SinkAggregatedCommitter支持聚合提交。
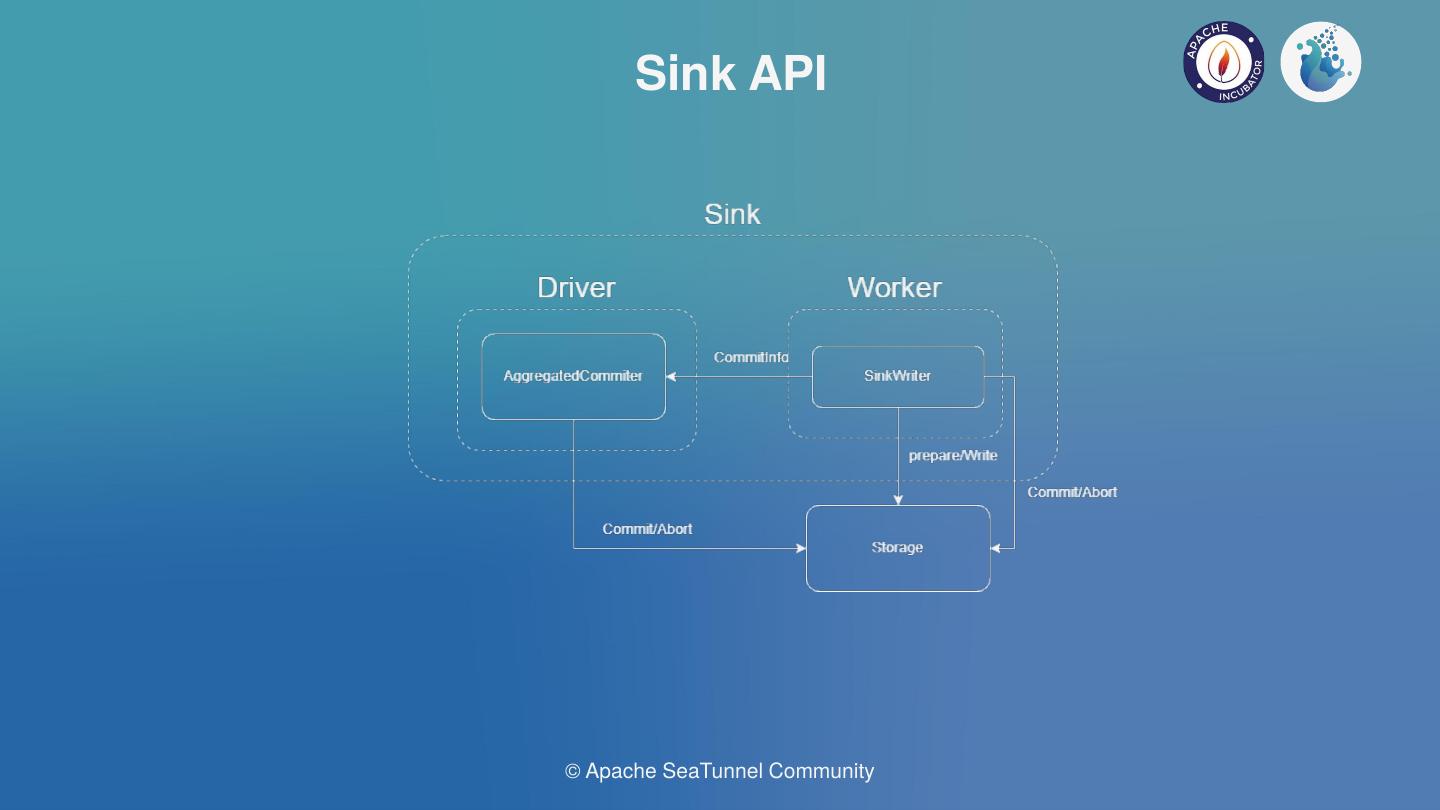
理想状态下,AggregatedCommitter单并行的在Driver中运行,Writer与Committer运行在Worker中,可能有多个并行度,每个并行度都有自己的预提交工作,然后把自己提交的信息发送给Aggregated Committer再进行聚合。
目前Spark和Flink的高版本都支持在Driver(Job Manager)运行AggregatedCommitter,worker(Job Manager)运行writer和Committer。
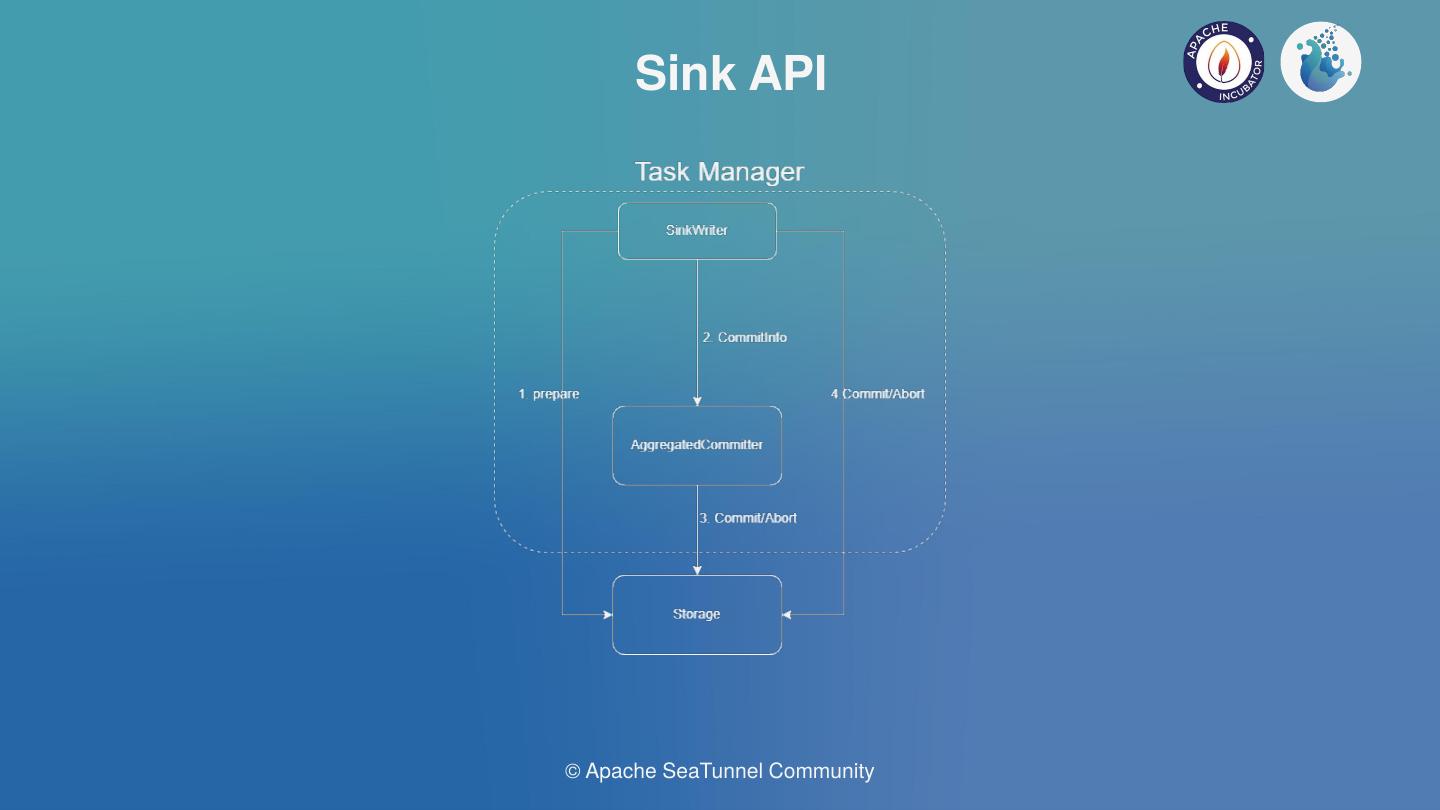
但是对于Flink低版本,无法支持AggregatedCommitter在JM中运行,我们也进行翻译适配的设计。Writer与Committer会作为前置的算子,使用Flink的ProcessFunction进行包裹,支持并发的预提交与写入工作,基于Flink的Checkpoint机制实现二阶段提交,这也是目前Flink的很多Connector的2PC实现方式。这个ProcessFunction会将预提交信息发送到下游的Aggregated Committer中,Aggregated Committer可以采用SinkFunction或Process Function等算子包裹,当然,我们需要保证AggregatedCommitter只会启动一个,即单并行度,否则聚合提交的逻辑就会出现问题。
感谢各位的观看,如果大家对具体实现感兴趣,可以去 Apache SeaTunnel (Incubating) 的社区查看api-draft分支代码,谢谢大家。
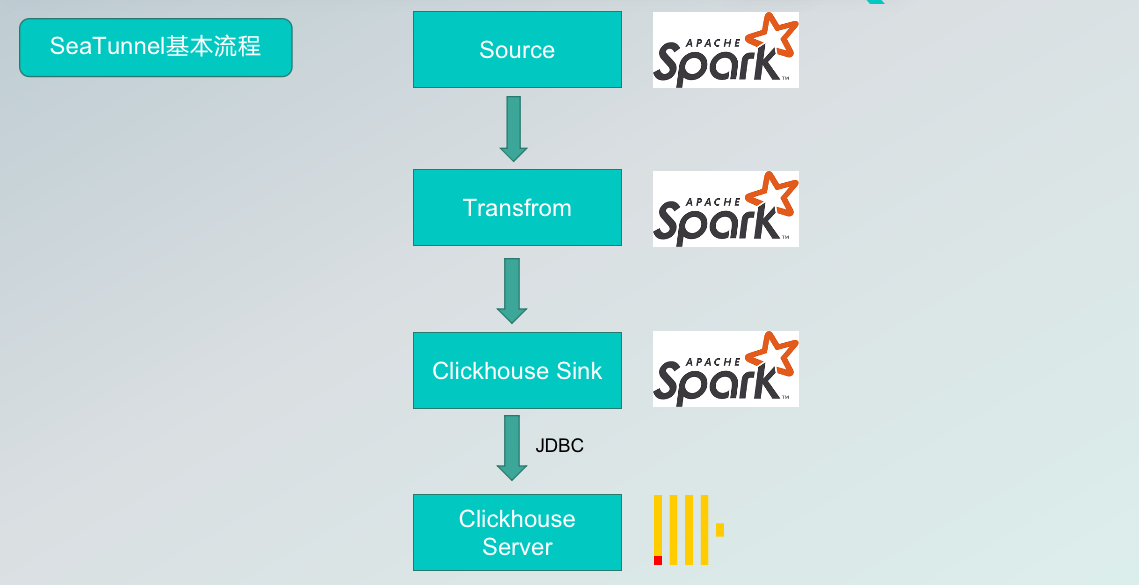
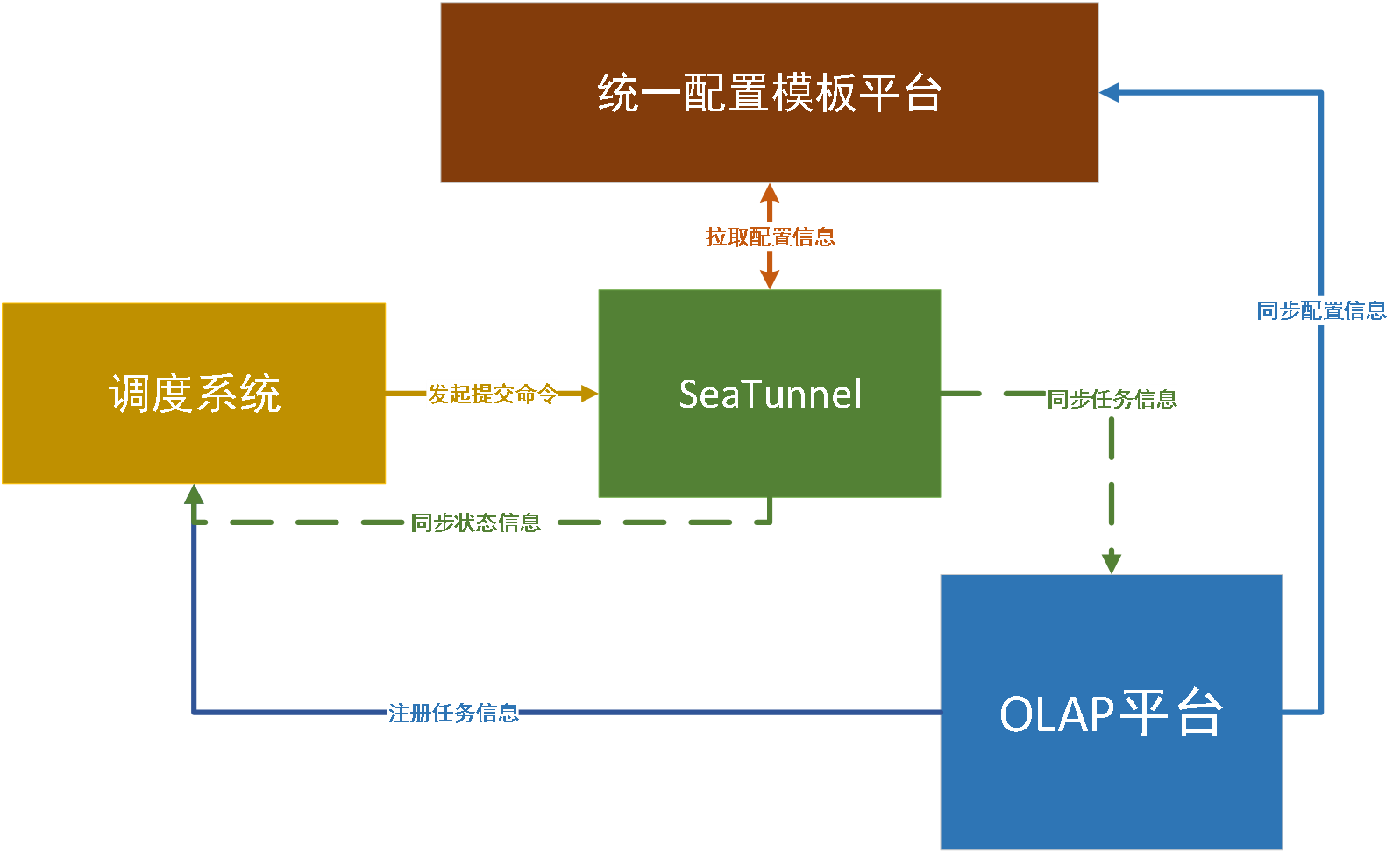
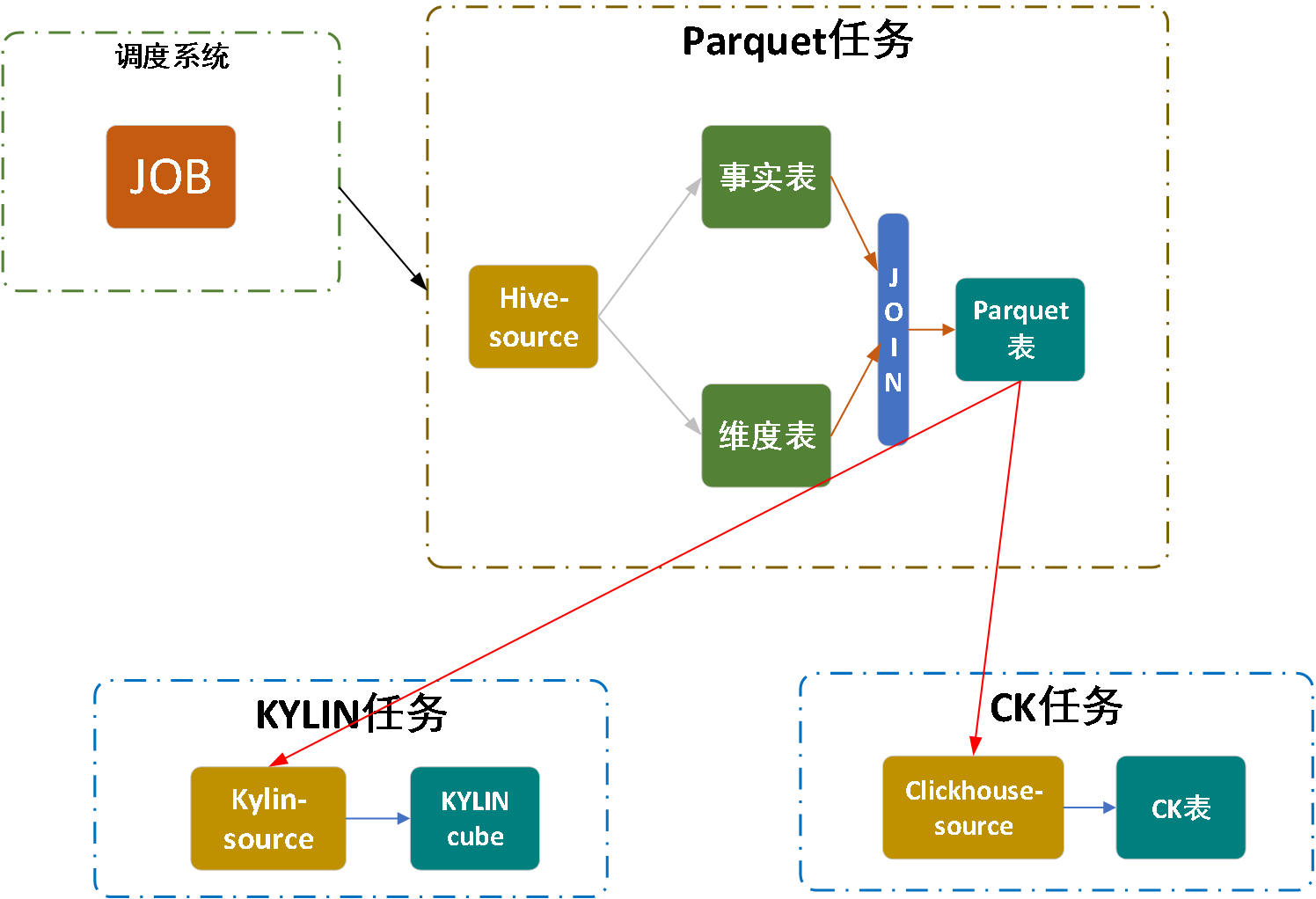
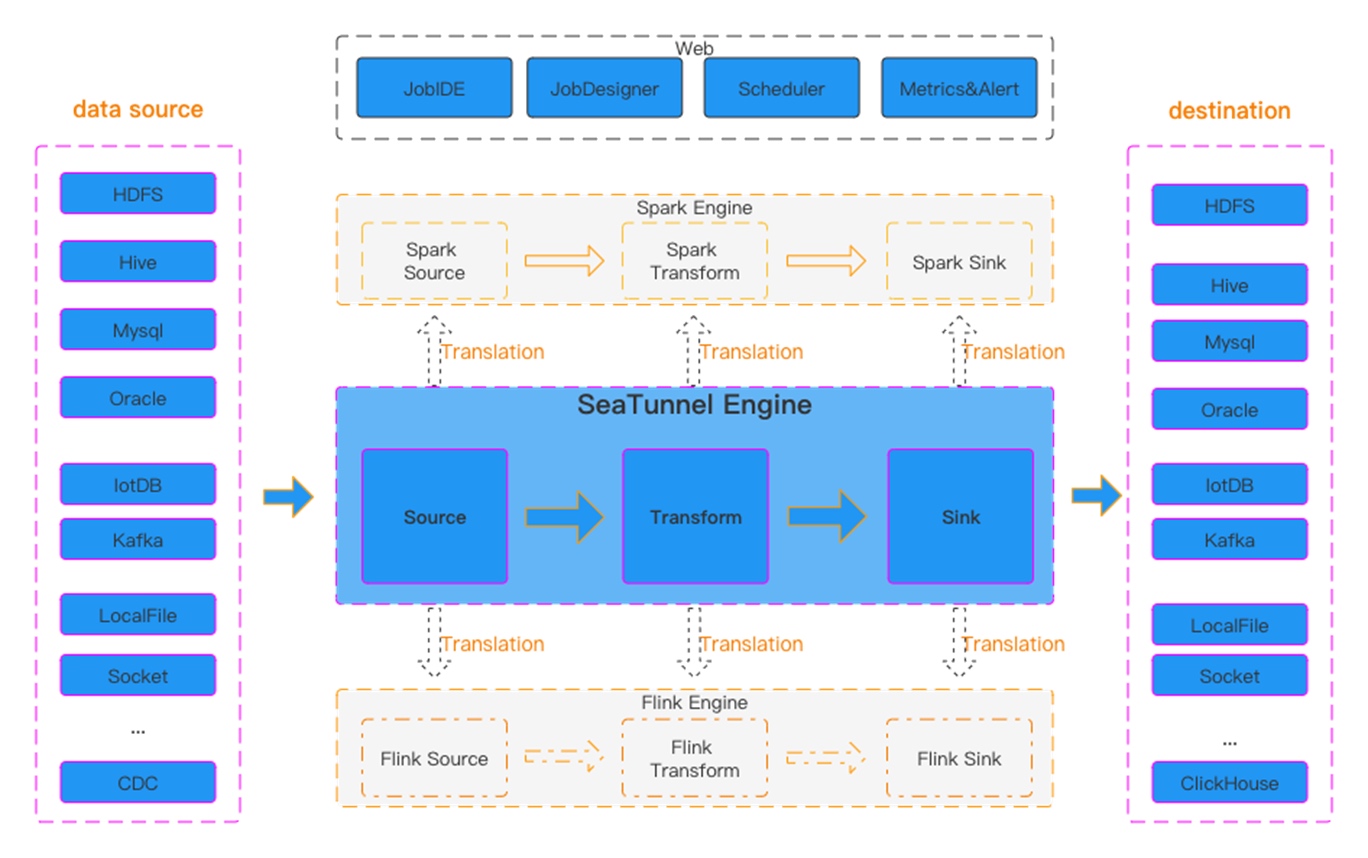 图一 Seatunnel工作流图
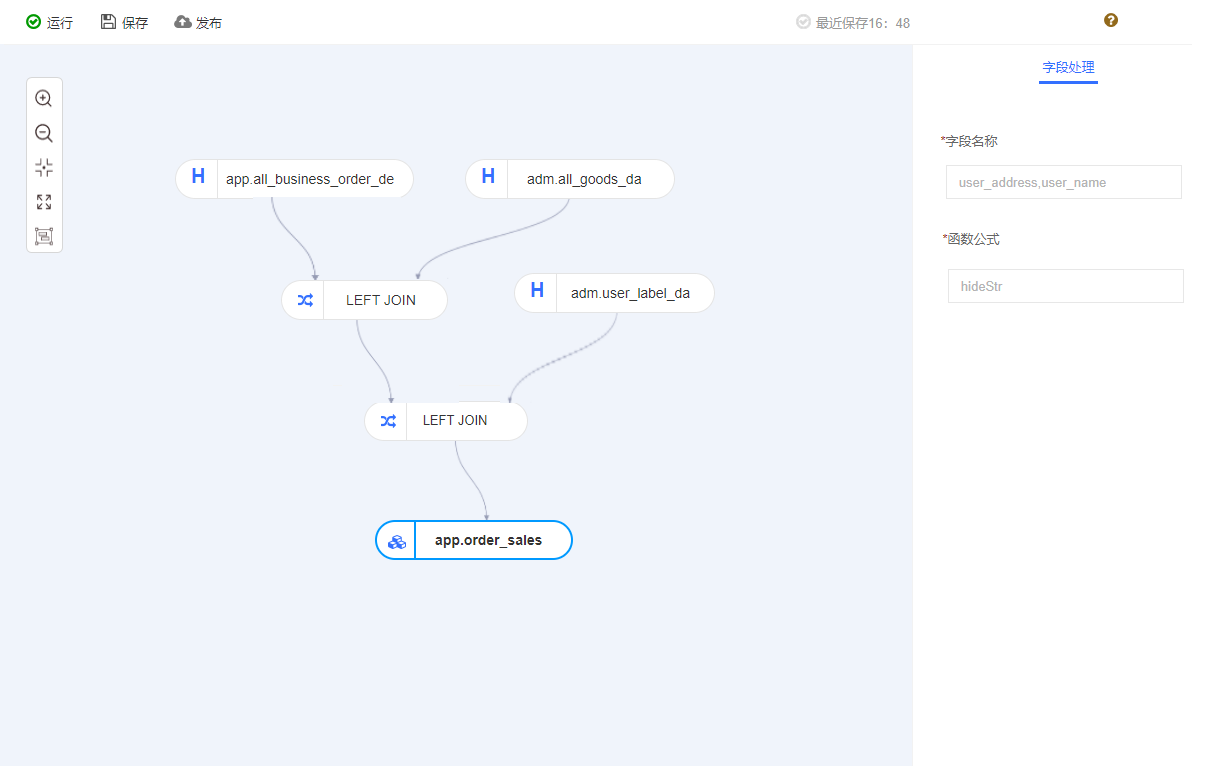
图一 Seatunnel工作流图 图二 数据同步日志信息
图二 数据同步日志信息